目前大多数web应用都是读多写少的环境,所以基本都是使用读写分离,即使用主库负责接收写入的请求,从库则负责读取的请求。使用多台数据库机器作为从库,来应对大量的读请求,进而提高web应用的迸发量。
Master
创建帐号用于主从同步
进入主库,执行以下命令假设创建账号为mysql-master,密码为mysql-master
grant replication slave on *.* to 'mysql-master'@'localhost' identified by 'mysql-master';
flush privileges; 刷新权限
导出数据
执行命令mysqldump -uXXX -pXXXX --master-data --single-transaction -R --databases your_db_name > /tmp/db.sql;。这里有两个点,--master-data和--single-transaction。
- 加上
--master-data之后,导出的sql文件的开头会多了一个语句是CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxx', MASTER_LOG_POS=xxx;,这里记录了执行数据库导出时候,主库的binlog文件以及其位置,用于后面的从库设置。PS:logfiel和logpos信息可以通过命令show master status;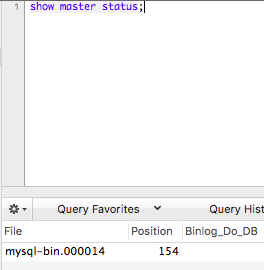
- 加上
--single-transaction之后,有类似于事物的效果,途中数据写入不会对导出的sql造成影响。
Slave
从库设置
进入从库,执行命令CHANGE MASTER TO MASTER_HOST='mysql-master',MASTER_USER='mysql-master',MASTER_PASSWORD='mysql-master';貌似这个可以写在配置文件中,写本文的时候还没有查到。。。
同步主库数据
将之前从主库导出的数据导入到从库中。导入数据的时候会执行到CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxx', MASTER_LOG_POS=xxx;,表示从主库的某一个点开始执行同步。
启动主从同步
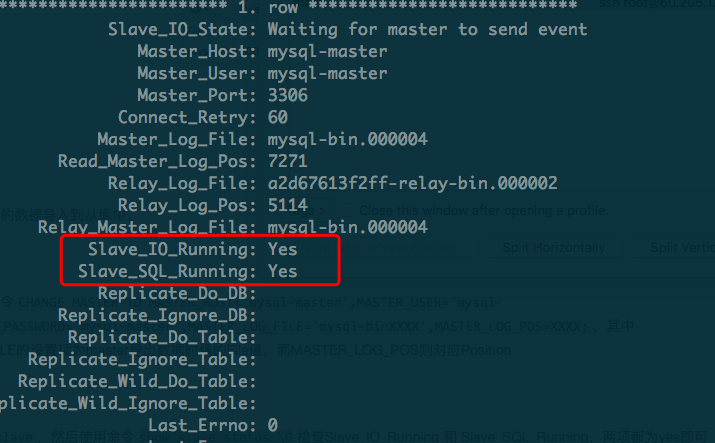
执行命令start slave,然后使用命令show slave status \G检查Slave_IO_Running 和 Slave_SQL_Running,两项都为yes即可,这样从库就会开始从主库导出数据的那个点往后继续同步数据了。
问题记录
Slave failed to initialize relay log info structure from the repository
问题描述与修复
使用的docker构建从库,当重新构建从库,执行start slave时候会提示此信息。此时可以执行以下命令修复
stop slavereset slaveCHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxx', MASTER_LOG_POS=xxx;,其中MASTER_LOG_FILE和MASTER_LOG_POS信息请看上面的“导出数据”start slave
PS:由于自建的博客,主库的MASTER_LOG_FILE和MASTER_LOG_POS变动不大,所以可以使用此方式,如果是线上运行的服务,不能采用如此粗暴的方式。
扩展信息
restart master和restart slaverestart master重置master的binglog,从000001开始重新记录。此命令一般只用于主从设置最开始,设置master。restart slave重置slave的relaylog,执行之后从库会从新生成relaylog,重新执行。